第二章 - 信息的表示和处理
第二章围绕整数与浮点数的位级表示展开,梳理字节序、补码、溢出、类型转换以及 IEEE 754 浮点数编码等核心概念。
数值溢出-overflow
计算机的表示方法使用有限数量的位来对应一个数字编码,因此,当结果太大以至于不能表示时,某些运算就会溢出(overflow)
整数运算和浮点数运算有不同的数学属性时因为它们处理数字表示有限性的方式不同——整数虽然只能编码一个相对较小的数值范围,但是这种表示时精确的;而浮点数虽然可以编码一个较大的数值范围,但是这种表示只能是近似的。
信息存储
大多数计算机使用八位的块,或者字节,作为最小的可寻址的内存单位,而不是访问内存中单独的位。
“位”、“字”、“字节”与“字长”概念的辨析 “位”是计算机数据存储的基本单位;“字”是计算机硬件总线一次性信息传输的基本单位,“字”的大小由计算机的位的大小决定(例如:64位系统的“字”即8字节);“字长”是CPU一次能并行处理的二进制位数,通常和“字”的大小匹配;“字节”一般为八个连续位组成的块,是计算机最小的可寻址内存单位。
为什么选用8位作为一个字节?这是因为8位二进制位表示的数值范围适中,适用性和拓展性都较为不错。若选用位数较小,则单位字节容纳的信息量有限,需要重复组合才能表示一个正常信息,对应硬件开销较大;若选用位数较大,则一个字节容纳的信息量较大,适用性和拓展性较弱,并且硬件设计的难度以及成本也会增加。字节位数的选择也是在硬件设计难度与成本、信息表示范围、适用性等方面的trade-off
机器级程序将内存视为一个非常大的一维字节数组,称为虚拟内存,所有可能地址的集合被称为虚拟地址空间。虚拟地址空间是一个展现给机器级程序的概念性映像,其实际实现是将动态随机内存存储器、闪存、磁盘存储器(磁盘)、特殊硬件和操作系统软件结合起来,为程序提供一个看上去统一的字节数组
由于在计算机中数据都是连续读取,我们可以把整个内存都看作是一个连续的一维数组。不同语言中的多维数组的本质就是以低维总数最为步长(stride)进行连续储存的一纬数组。例如,C语言中的二维数组 A[1][7],表示x纬长度为8(低维),y纬长度为2的二维数组,其在内存中则是步长为8连续储存的一维数组,如图一所示:
内存地址: [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10][11][12][13][14][15]
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
二维视角: |A[0][0]|A[0][1]|A[0][2]|A[0][3]|A[0][4]|A[0][5]|A[0][6]|A[0][7]|
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
|A[1][0]|A[1][1]|A[1][2]|A[1][3]|A[1][4]|A[1][5]|A[1][6]|A[1][7]|
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
内存实际: [A[0][0], A[0][1], A[0][2], A[0][3], A[0][4], A[0][5], A[0][6], A[0][7],
A[1][0], A[1][1], A[1][2], A[1][3], A[1][4], A[1][5], A[1][6], A[1][7]]
步长(stride): 行步长 = 8个元素 × 元素大小
列步长 = 1个元素 × 元素大小
索引计算: A[y][x] = 基地址 + (y × 行步长) + (x × 列步长)图一
指针
指针是一个特殊的变量,其值为另一个变量(或对象)在内存中起始字节的地址。指针本身的大小由**编译器的内存模型(也是对应程序的内存模型)**决定:在常见的 64 位程序中,指针通常占据 8 个字节;而在 32 位程序中,指针占据 4 个字节
指针提供了引用数据结构(包括数组)的元素的机制。与变量类似,指针也有两个方面:值和类型。它的值表示某个对象的位置,而它的类型表示那个位置上所存储对象的类型(比如整数或者浮点数)
指针所存储的对象类型信息为解指针操作支撑。我们需要知道指针的数据类型才能知道需要向初始地址后读取几位数值以获取正确信息,同时也才能知道该将输出传给什么类型的计算单元进行运算。对指针数据的i位数据访问,即是访问在指针指向的数组初始地址的基础上向后偏移 i*sizeof(指针数据类型) 大小的空间。
十六进制表示
Skill - 十六进制到二进制的转换
十六进制的最大优势,在于它和二进制之间存在天然的位宽对应关系:1 位十六进制数恰好对应 4 位二进制数。因此,从十六进制转二进制时,不需要做除法或乘法,只需要把每一位单独展开即可。
例如:
0x0→00000xA→10100xF→1111
于是 0x3A5 可以直接写成:
0011 1010 0101
这种转换方式在阅读机器码、观察内存布局以及分析位掩码时非常高效,因为十六进制本质上就是二进制的紧凑写法。
Skill - 二进制到十六进制的转换
二进制转十六进制时,可以从最低位开始每 4 位一组进行切分;如果最高位不足 4 位,就在左边补 0。分组完成后,再把每组二进制替换成对应的十六进制字符即可。
例如:
110101101 → 0001 1010 1101 → 0x1AD
这也是为什么程序员在描述位模式时更偏爱十六进制:相较于很长的二进制串,十六进制既保留了位级结构,又更适合人眼快速扫描。
Skill - 十进制到十六进制的转换
十进制转十六进制最常见的方法是不断除以 16 取余,再将余数倒序排列。
例如将十进制 419 转换为十六进制:
419 ÷ 16 = 26 ... 326 ÷ 16 = 1 ... 10(A)1 ÷ 16 = 0 ... 1
倒序写出即为:0x1A3
如果数值本身已经具有明显的 2 的幂结构,也可以直接借助二进制作为中间层完成转换。对于程序设计而言,熟悉这三种表示之间的切换,本质上是在训练自己从“数值”与“位模式”两个视角同时理解同一个数据。
字数据大小
每台计算机都有一个字长(word size),它决定了指针和地址相关数据的典型位宽。由于虚拟地址正是由这样的位宽来编码的,所以字长会直接影响虚拟地址空间的理论上限。对于一个字长为
计算机的字长并非一成不变,而是随着硬件工艺和软件需求的演进而变化。过去常见的是 32 位 架构,理论可寻址空间约为 4GB;后来逐渐过渡到 64 位 架构,理论地址空间上限也扩展到了 16EB(实际处理器通常会低于这个理论极限)。
这类演进通常会尽量保留向后兼容能力,因此,64 位系统往往可以在具备兼容库和运行环境的前提下运行 32 位程序。例如,当程序 pro.c 用如下方式编译:
linux> gcc -m64 pro.c -o pro
得到的是 64 位程序,它通常需要在 64 位执行环境中运行。另一方面,如果程序用下述方式编译:
linux> gcc -m32 pro.c -o pro
得到的是 32 位程序,它常常可以在 32 位系统上运行,也常常能够在支持兼容模式的 64 位系统上运行。
因此,我们说“32 位程序”还是“64 位程序”,核心区分点在于程序采用了哪一种编译模型和地址模型;至于它最终能否运行,还取决于目标机器和操作系统是否提供相应的支持环境。
这也是在之前指针大小定义与编译器对应的编译模型相关的原因
除了指针大小外,不同类型程序对相同数据类型所占大小也有所不同,具体异同如下图所示
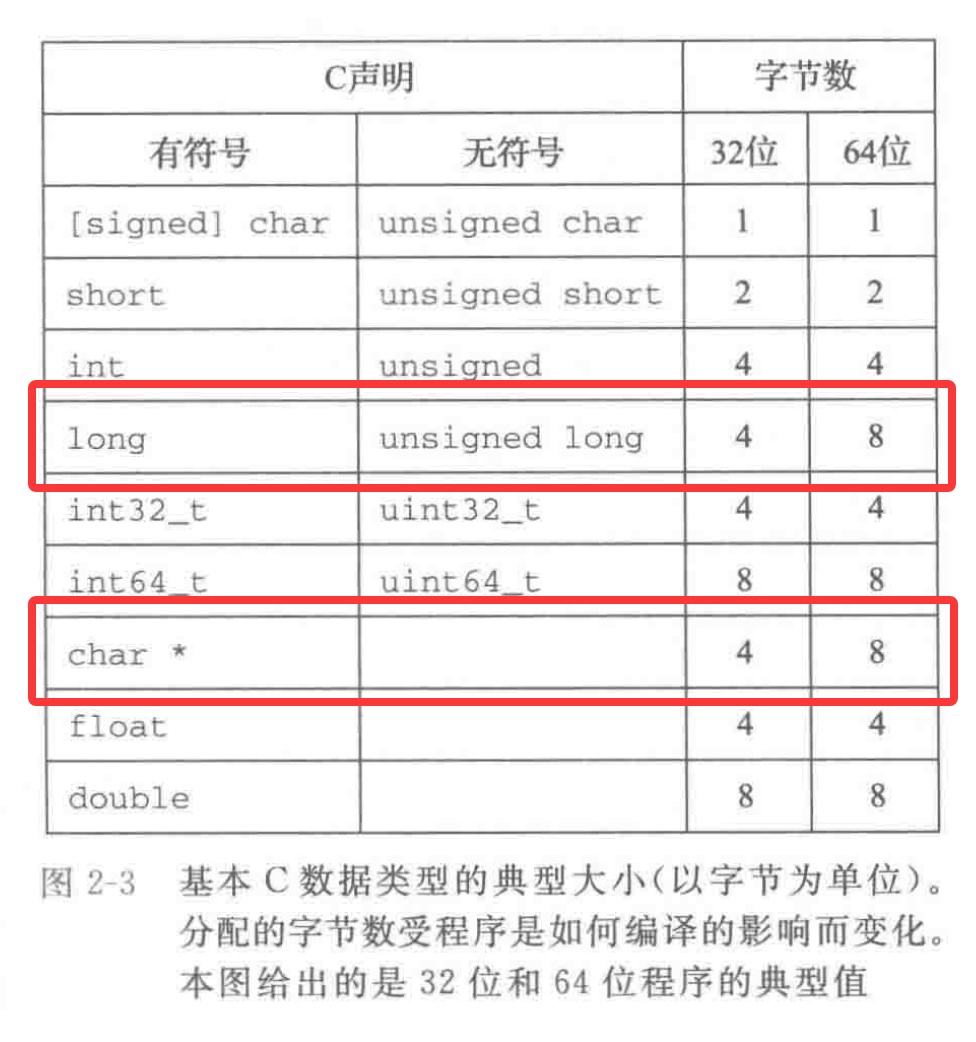
为了避免由于数值类型典型的大小和不同编译器设置带来的奇怪行为,ISO C99 引入了一类数据类型,其数据大小是固定的,不随编译器和机器的设置而变化,其中就有数据类型 int32_t,int64_t ,它们分别代表4字节和8字节
大部分数据类型都编码为有符号数值,除非有前缀关键字 unsigned或对确定大小的数据类型使用了特定的无符号声明。数据类型 char 是个例外。尽管大多数编译器和机器将它们视为有符号数,但 C 标准不保证这一点。
C 语言标准规定
char的符号性是“由实现定义的”,编译器和硬件架构决定了它是signed还是unsigned
程序的可移植性可分为:硬件架构、操作系统、编译器与语言以及依赖库与环境四个层面,其中硬件架构包括字长大小、字节序、指令集拓展、内存对齐等差异;操作系统包括系统 kernel 调用方式、系统路径/换行符表示方式等差异;编译器包括自动优化程度、编译器选项等差异;依赖库与环境包括依赖库版本、链接方式等差异
寻址和字节顺序
这一节的重点在于理解两个问题:多字节对象在内存中究竟按什么顺序存放,以及指针为什么只需要记录对象起始字节的地址。把这两个问题想清楚之后,再回头看大小端存储法、地址递增方向以及连续内存布局之间的关系,就会顺畅很多。

大小端法即数据存储方式的差异:我们可以将一串字节序列按照从左至右依次增大进行编号。若将编号后的数据按照从左至右依次储存,则称为大端法;反之,若将数据按照从右至左的方式依次存储,则称为小端法
需要注意一点的是,在我们常规计数逻辑中,从左至右数值越大。但在进制数值中,越靠近右边数值的位数越“高”。理清“高低”和“大小”的区别后再去理解“大/小端法”的定义就轻轻松松了。
字符串的表示
C 语言中的字符串,本质上是一个以 NULL(值为 0)字符结尾的字符数组。每个字符都由某种字符编码表示,最常见的是 ASCII 码。因此,如果我们以参数 "12345" 和 6(包含结尾的终止符)来运行例程 show_bytes,就会得到结果 31 32 33 34 35 00。其中,十进制数字 x 的 ASCII 编码恰好是 0x3x,而终止字节的十六进制表示则是 0x00。也正因为如此,文本数据通常比纯二进制数据具有更强的平台独立性。
ASCII 编码的存在,使得文本数据能够在具备相同编码规则的不同系统上自由迁移而不损失其含义,展现出了强大的独立性。这并非 ASCII 的特例,其背后隐藏着计算机体系设计中很重要的一种思想——中间层(抽象层)表示。
在发展过程中,不同工程师对软硬件的设计理念并不相同,这让“代码的跨平台运行”成为一个长期存在的问题。建立中间层,就是解决这类问题的典型方式:向下适配不同的底层架构,向上提供统一的抽象接口。
我们在系统设计的很多地方都能看到这种思路。例如,操作系统通过硬件抽象层屏蔽不同 CPU 和总线的差异;Java 虚拟机通过统一的字节码中间层实现“一次编写,到处运行”;在异构计算领域,类似 SYCL 这样的方案也会借助中间表示,把同一份代码适配到 CPU、GPU 或 FPGA 等不同处理机上。
因此,字符串编码表面上看是在讨论“字符如何存储”,但往深一层看,它也揭示了计算机系统设计中的一个普遍规律:先建立统一表示,再通过中间层适配不同实现。
布尔代数
布尔代数在近期一个比较常见的应用场景,就是 Attention 流程中的掩码机制。掩码机制通过创建一个 0/1 布尔矩阵,用来控制序列中不同 Token 之间注意力权重的连通状态。在文本生成的自回归过程中,我们使用的是一个下三角布尔矩阵:主对角线及下三角区域为 1,严格上三角区域为 0。其中,值为 1 的区域代表模型被允许关注当前词及历史词;值为 0 的区域则强行屏蔽尚未生成的“未来词”。这种设计严格遵守了文本生成的时间因果律,因此被称为因果掩码。
从这个应用中也可以看出,布尔代数在计算机算法里的一个核心作用就是充当“门控”。它用最基础的 0 和 1 表示某种关系或信息流动是否存在,就像电路中控制灯泡亮灭的开关一样,决定一条路径是否被允许通过。

布尔代数的运算
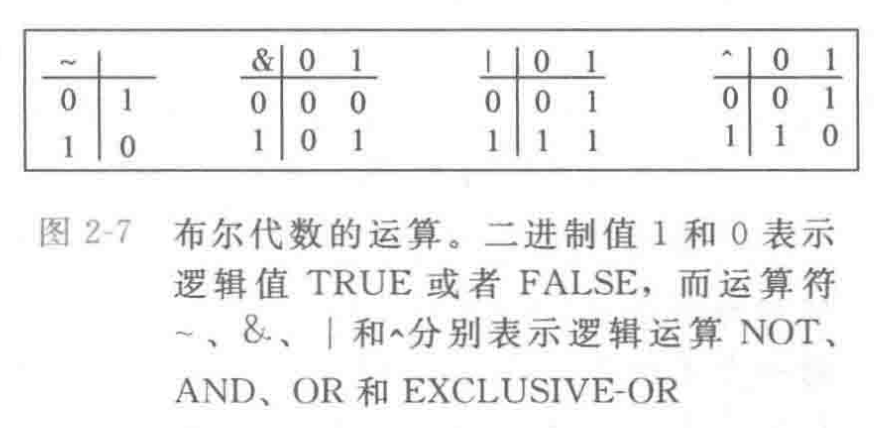
C语言中的逻辑运算
C 语言中的逻辑运算符包括 !、&&、||。它们和位运算符最大的区别在于:逻辑运算关心“真 / 假”,位运算关心“每一位上的 0 / 1”。
例如,对于任意非零值 x,表达式 !x 的结果恒为 0;只有当 x == 0 时,!x 才为 1。同样地,a && b 与 a || b 最终返回的也是逻辑意义上的 0 或 1,而不是把两个数逐位做与、或运算。
还需要注意一点:逻辑运算具有短路特性。对于 a && b,如果 a 已经为假,则 b 不再求值;对于 a || b,如果 a 已经为真,则 b 也不会继续求值。这个特性在控制流程中非常有用,但如果把它和位运算混淆,就很容易写出含义错误的条件表达式。
C语言中的移位运算
这里需要注意“算数右移位”和“逻辑右移”的差异:逻辑右移是正常将二进制码向右方向移动k位,空出部分用0进行补充;算数右移同样也是将二进制码向右方向移动k位,但是空出部分填充k个最高有效位的值。二者的差异由于补码机制的存在而产生。下面对此进行论证。
设存在一个位宽为
现设定一个移位量
根据逻辑右移定义,对整数
提取公因式得到:
联立
由于余数
对
在二进制运算中,数值相减对应补码加法。
则
综上所述,我们将对二进制码向右移动k位,空出的k个高位用原最高有效位值填充的过程称为算术右移
移位运算(k ≥ w 时)

移位运算的优先级要小于加减法的优先级
整数的表示
补码编码
对于许多应用,我们还希望表示负数值。最常见的有符号数的计算机表示方式就是补码(two’s-complement)形式。在这个定义中,将字的最高有效位解释为负权(negative weight)。我们用函数
对向量
让我们来思考一下为什么通过将最高位设置为负权重来实现负数表示。 先引入被我主动忽略而没有写入 note 的“常识”: 对于一个
位的二进制码,其能够表示的无符号整数范围为 。注意,这里是用连续的区间进行表示,代表其能表示其中所有的整数值。 对于有符号整数编码(补码编码),在最高位引入负权重后,最高位表示的数值为 ,余下 位依旧是正权重,其能表示的范围为 。 位整体能表示的范围为二者加和,即为:
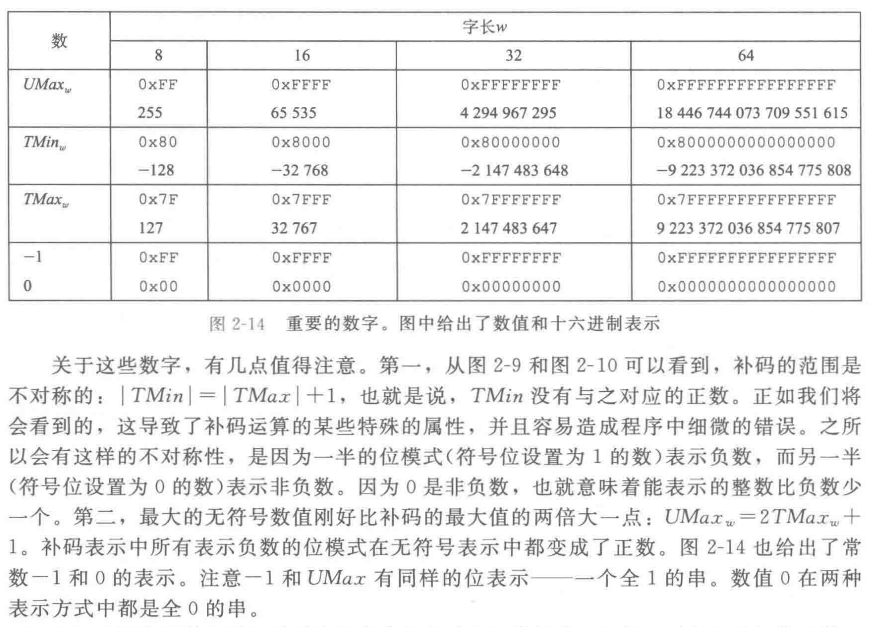
补码具有不对称性,且满足
强制类型转换的结果保持位值不变,只是改变了解释这个位的方式

这里有一个非常重要的公式,对于同一二进制位所表示的无符号数 us 与有符号数 s 之间存在下述关系:
根据这个公式我们可以知道:处于有符号-无符号类型范围交集内的数值进行强制类型转换时,数值不会发生改变(因为二进制位相同)。
这里可以先把握一个核心结论:强制类型转换通常不会改动底层位模式,改变的只是解释这些位的方式。也正因为如此,同一串比特在无符号与补码语义下,可能对应完全不同的数值。


在C语言编程中要十分注意类型的隐式转换问题
拓展数字的位表示
这部分很简单,可以参考“逻辑右移”进行类比记忆:无符号类型高位拓展0即可,有符号类型拓展最高有效位数值即可。
为什么有符号负数(最高位为 1)在扩展时必须连续补 1 才能保持值不变? 因为在补码表示中,最高位拥有负权重1。这些新增的 1 拥有正权重,它们的几何级数和抵消了新老符号位之间产生的负权重差值。
上述解释的数学证明过程也很简单,设原
向左扩展一位后,设新的最高位为
二者相减得到:
故为了使移位后的数值等价于原数值,
证得:扩展后的新最高位
数字位的截断
无符号数
整数运算

这个图像还挺有意思,直观表示出两位四位字长的数值相加的结果分布规律
算数运算溢出
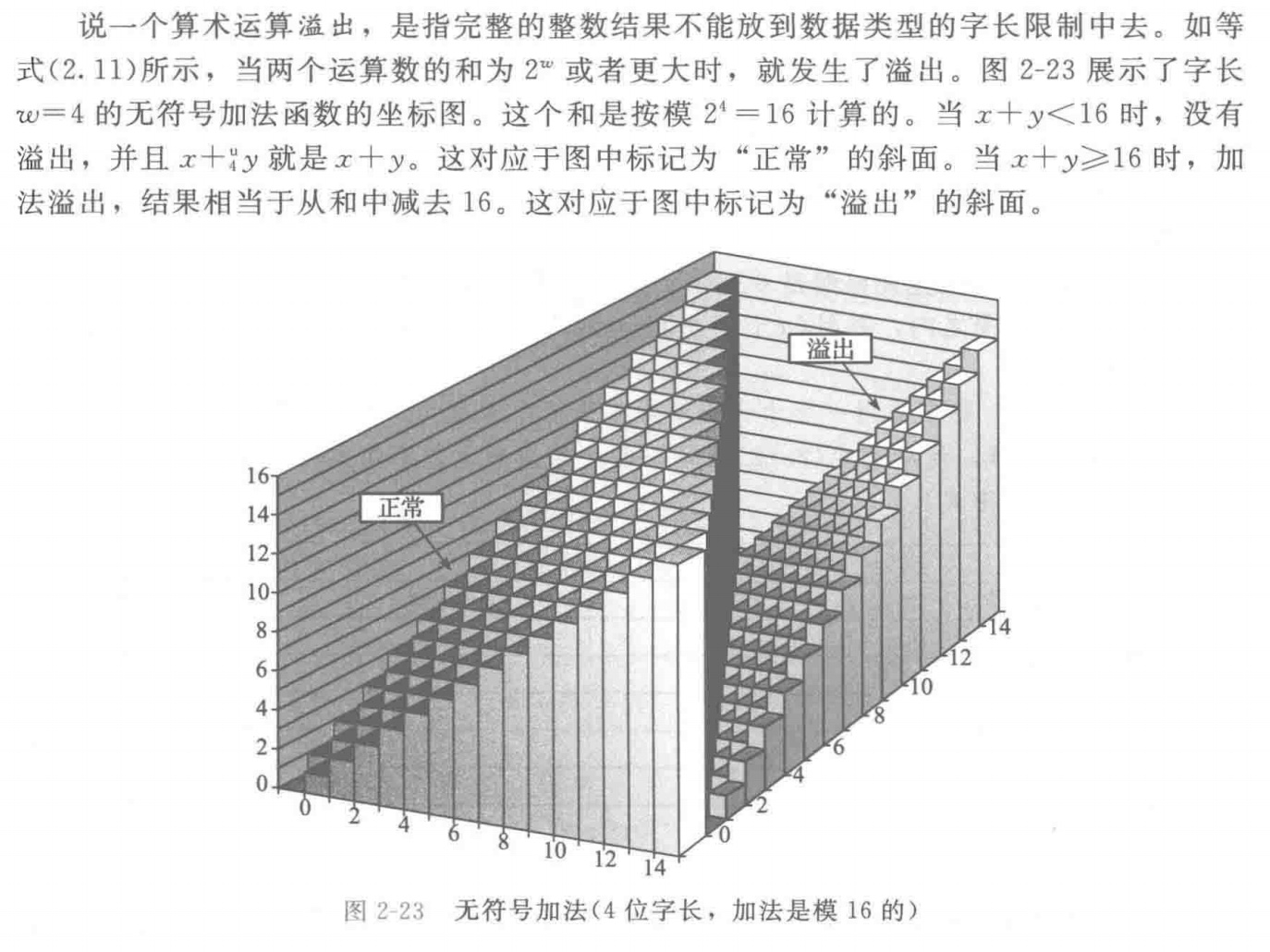
无符号加法
判断是否发生了算数运算溢出:看两数加和是否小于任意加数

有符号加法

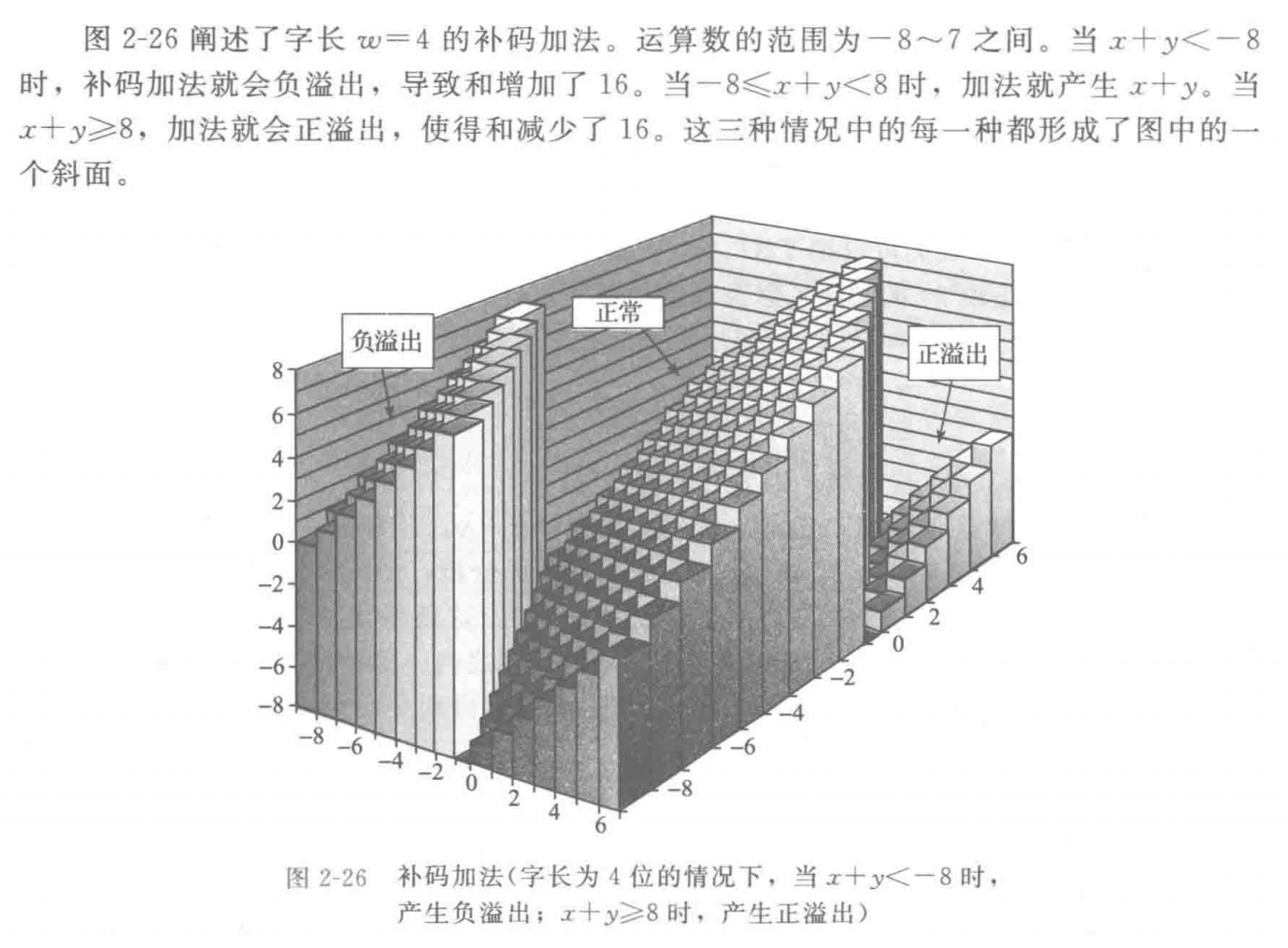
补码加法中的溢出判断:观察加和结果是否与加数符号相异
补码的非需要注意一点:
补码非的操作。
这个操作的原理很简单:对于一个给定的补码数值 $Value_0 $ 的二进制位取反得
,$Value_0 + Value_1 $ 的二进制位全1。二进制位全1的数加上1会发生数值溢出,结果变为0。这就是为什么计算补码非采用取反加1的原理。
补码乘法
补码乘法在位级上的本质,仍然是先计算乘积,再将结果截断到固定字长。也正因为如此,补码乘法和补码加法一样,都可能出现溢出:当真实数学结果超出当前字长所能表示的范围时,高位会被直接丢弃,最终保留下来的只是模
从程序行为上看,这意味着“乘法算出来的结果”不一定等于数学上的真实乘积,而是等于真实乘积对机器字长取模后的位模式解释结果。因此在涉及边界值、放大倍数运算以及整数优化时,乘法同样需要警惕溢出问题,尤其是有符号数相乘后符号突然翻转的情况。
乘以常数
早期计算机处理器由于缺乏硬件乘法单元,乘法运算通常需要通过软件模拟或微码实现,将其拆解为多次循环加法,导致执行代价极高。为了提升性能,编译器会利用位权转换进行优化:将乘法指令拆解为左移运算与加法的组合。例如,计算
除以2的指数幂
注意:补码的除法需要进行偏执(biasing)处理
Summary of the Integer
整数表示总结:从权重模型到溢出风险
整数的表示本质上是二进制位的加权求和。在给定位数的序列中,无符号数每一位均为正权重;而补码则将最高位定义为负权重。这种权重分配的差异,导致了相同位数下数值范围的移动:补码通过牺牲一半的正数空间,实现了对负数的表示,并产生了一个不对称的取值范围(即
这种表示差异在强制类型转换时会引发风险:当无符号数与有符号数相互转换时,底层位模式虽未改变,但最高位的权重解析发生了“正负反转”,从而导致数值溢出或符号突变。Java 等语言为了根除此类逻辑陷阱,在设计上选择了仅保留有符号整型。
然而,即便统一了符号类型,算术运算溢出依然是无法回避的底层限制。由于寄存器宽度固定,当计算结果超出该类型承载的权重极限时,高位将被截断,产生违逆直觉的结果。在进行高精度计算或涉及边界条件的开发时,开发者必须具备防御性编程意识,通过溢出预测或结果校验(如利用 Math.addExact 等原子操作)来确保程序的鲁棒性。
浮点数
二进制浮点数

二进制浮点数的表示很有意思,参考整数科学计算的定义来设计浮点数的二进制表示规则。上述规则很好解决了二进制位表示浮点数的问题,但依旧存在一些问题。由于2作为底数的幂函数增长速率较低,因此难以表示较大数值。例如,表示
是101后面跟200个0才能表示,对数据位的利用率较低。基于这个问题,工程师提出了另一种浮点数表示方式


IEEE 浮点数标准下数值分为规格化值、非规格化的值以及特殊值
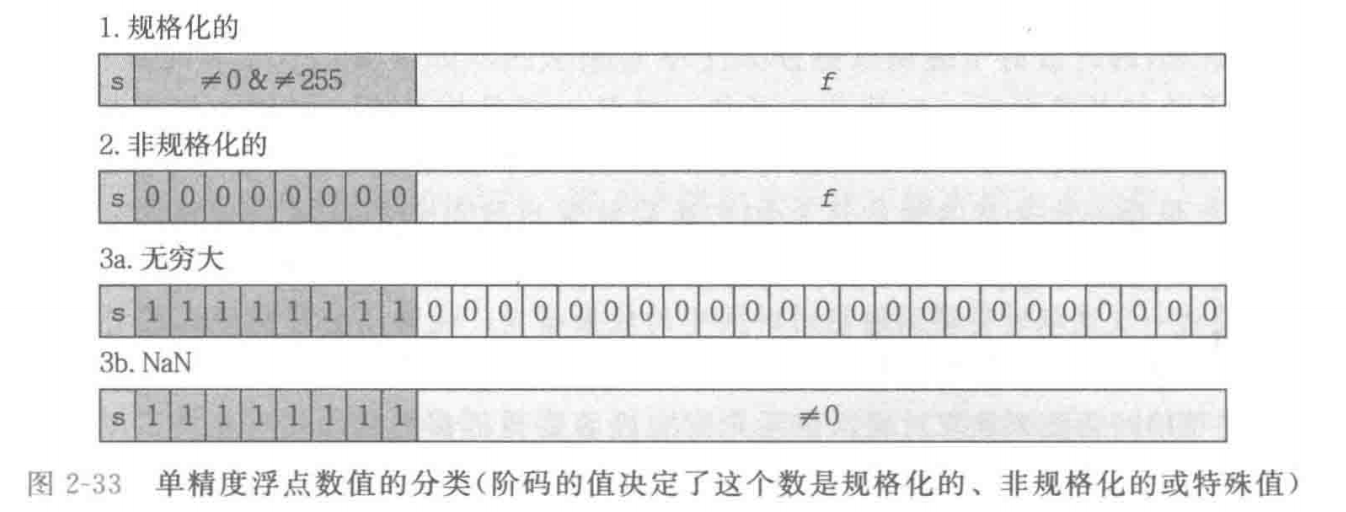
规格化值为浮点数的一般表示。
在规格化值表示规则中:
其中,E 表示 exponent(给浮点数加权的阶码值),e 表示二进制位中 exponent 区域的值,Bias 是标准固定的常量,固定大小为
其中,f 表示 fraction(尾数),即小数部分的值。因为总能调整浮点数的阶码使尾数处于
在非规格化值的表示中:
之所以将阶码值设置为
在非规格化值中,尾数部分直接等于 f 值,仅表示小数部分值,为 0 的表示提供可能。
非规格化值有两个作用,一是为0的表示提供可能,二是通过逐渐溢出的方法均匀表示非常接近0的数值
在特殊值的表示当中:
若小数域(frac)全为0:s 位为0时表示正无穷,为1时表示负无穷
若小数域(frac)不全为0:此时值被称为 NaN

为什么阶码值全1的特殊值情况时,若小数域不为0的情况都表示NaN值?这样不会浪费很多表示情况吗?
这并不算“浪费”,而是 IEEE 754 刻意保留的一类异常编码。在该标准中,指数全 1、尾数全 0 用来表示
+∞或-∞;指数全 1、尾数非 0 则统一表示 NaN。这样设计的好处是:硬件和软件可以很快把“正常有限值”“无穷大”“非法或未定义结果”区分开来。此外,NaN 并不是只有一种位型。保留多种 NaN 编码,一方面可以区分 quiet NaN 和 signaling NaN,另一方面也给部分实现留下了存放诊断信息(payload)的空间。对普通编程而言,更重要的是理解它的语义:当运算结果已经失去正常数值意义时,系统需要一种特殊值把这种异常状态继续传播下去,而 NaN 正是为此而存在的。
是否可以利用 NaN 的小数域传递 debug 信息?可以,但它更适合作为底层调试或运行时系统中的诊断技巧,而不适合作为普通业务代码中的通用方案。
从 IEEE 754 的设计上看,NaN 的尾数字段(payload)确实可以携带额外信息,因此一些底层系统会利用它来区分错误来源,或在数值管线中保留异常上下文。但要注意,这种做法的可移植性并不好:不同硬件、编译器、指令优化以及后续浮点运算,都可能改变 NaN 的具体 payload,甚至把 signaling NaN 转成 quiet NaN。
因此,更稳妥的理解是:NaN payload 可以承载诊断信息,但它不是可靠的跨平台数据通道。在调试器、虚拟机、数值库或特定运行时里,这是一种有价值的技巧;在日常应用开发里,则不应把它当成稳定的业务编码手段。
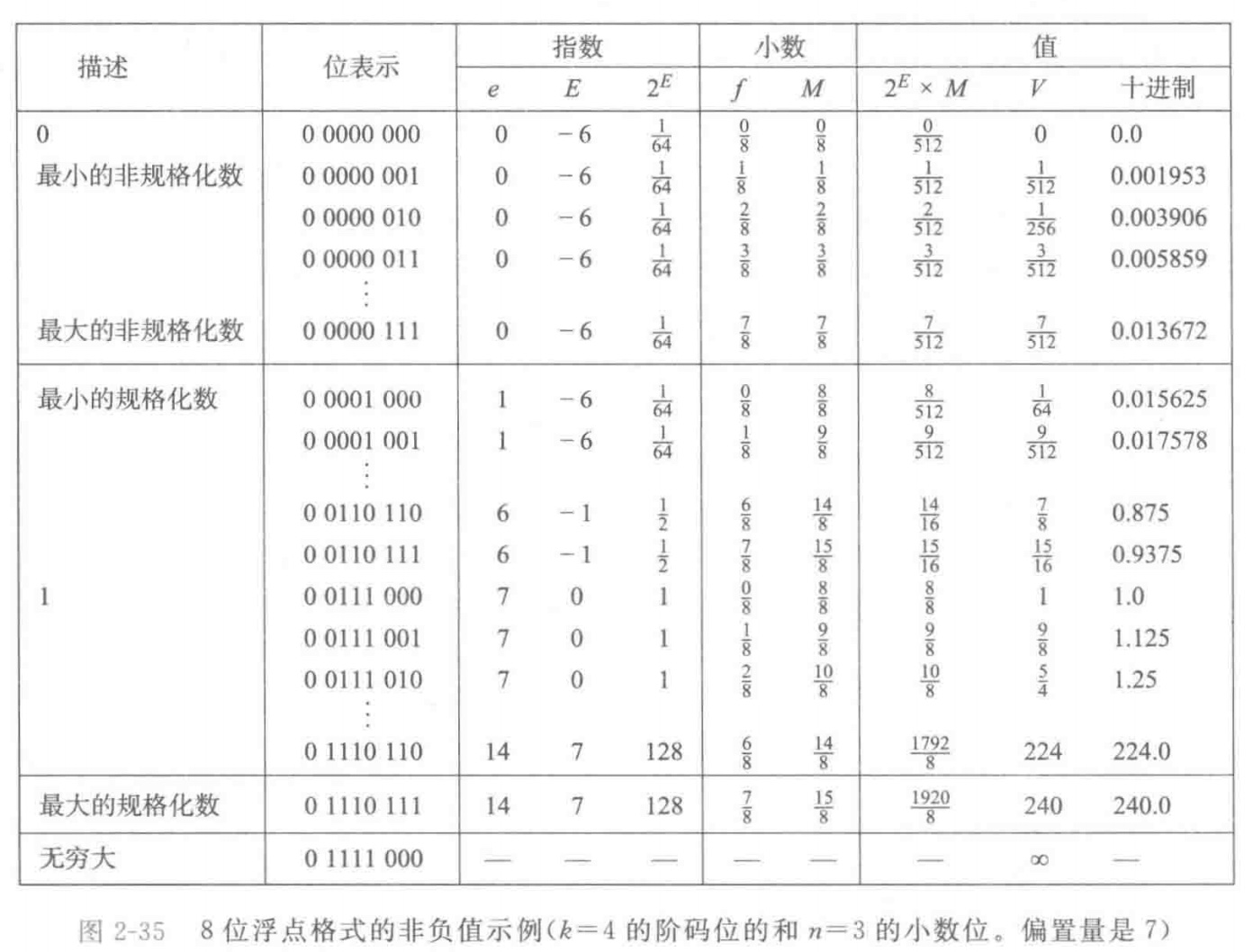

为什么超过 240 就溢出到正无穷?关键在于:浮点溢出不是像整数那样简单截断高位,而是要先判断结果是否超出了该格式可表示的最大有限值。
以单精度浮点数为例,指数域一共 8 位,去掉全 0 和全 1 这两类保留编码后,最大的有限指数对应的真实阶码是
127。一旦运算结果的规格化表示要求的真实阶码继续增大,就已经无法落在“有限规格化数”的编码区间内了。按照 IEEE 754 标准,这种**上溢(overflow)**的默认结果会被置为+∞或-∞,而不是保留某个被截断后的普通数。换句话说,浮点数和整数的处理规则不同:
- 整数溢出更像是固定位宽下的位模式截断;
- 浮点溢出则遵循 IEEE 754 的异常结果规则。
正因为标准专门保留了“阶码全 1”这一整段编码空间,硬件在检测到结果超出最大有限值时,就会直接生成无穷大。这种规则比“继续截断成某个普通数”更安全,因为它能把“结果已经失真”这个事实明确暴露出来,避免程序误把一个错误的大数当成正常结果继续计算。

相同数值的浮点数和整数二进制位表示内容具有部分重合
Q:如何实现 float 到 int 的类型转换? A:核心思路是:先解析浮点数的符号位、阶码和尾数,并在规格化数情况下补回被隐藏的最高位
1;随后根据真实阶码移动尾数中的二进制小数点,把它对齐到整数位置。若结果仍带有小数部分,则在转换为int时按向零截断处理;若真实数值已经超出int的可表示范围,那么在标准 C 语义下,这类转换属于超出范围的情况,不能简单把它理解为统一返回某个普通整数值。因此,从位级角度看,
float -> int的关键并不在于“重新编码”,而在于:恢复有效数字、根据阶码对齐、丢弃小数部分,并检查结果是否还能落入整数类型的范围内。
Q:为什么 float 设置为阶码位为 8 位? A:这是工程师在数值动态范围以及精度等问题上的 trade-off。
Q:浮点数加法为什么会出现精度损失? A:本质原因在于:两个浮点数相加前,必须先把它们的阶码对齐。若其中一个数明显更小,它的尾数就需要向右移动,以匹配较大数的阶码;而在右移过程中,低位有效数字会被不断挤掉,最终可能完全丢失。这样一来,较小的那个加数即使数学上不为 0,在机器表示里也可能因为精度不足而“加不上去”。
由这个过程也能看出,发生精度损失的临界点与尾数有效位数直接相关。对于 32 位单精度浮点数来说,尾数有 23 位,再加上隐含的最高位
1,总共约 24 位有效精度。因此当数值达到附近时,继续加上 1 这类更小的量,就可能已经无法改变结果了。
Q:如何解决浮点数加法的精度损失问题? A:解决方案很简单,可以创建一个累加器,将较小数值的数累加到累加器中,待数值较大后再进行加和运算。
注意:由于浮点数以幂函数作为权重的特点,浮点数难以表示连续相邻数据。相反,随着数值绝对值的增大,相邻两个浮点数之间的间隔会成倍拉大,呈现出阶梯状发散的稀疏特性。
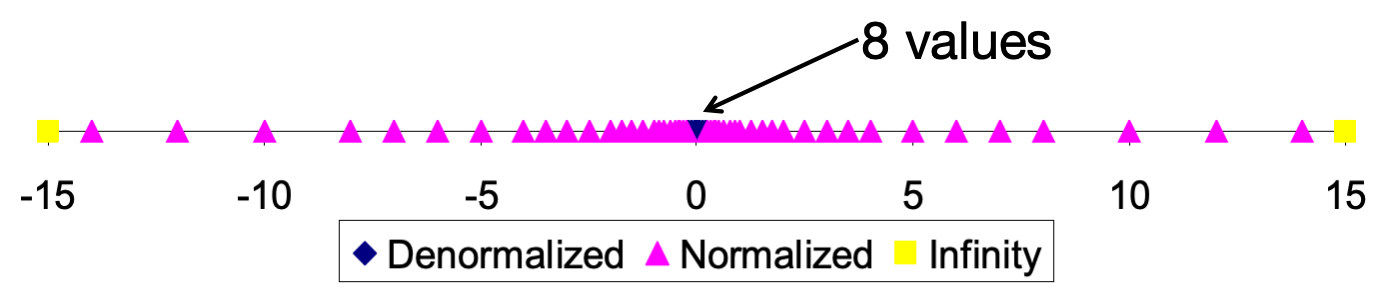
舍入
浮点数的舍入存在四种方式,一般情况下默认以第一种方式为主:
向偶数舍入:向最接近的值舍入,遇到中间值时向偶数舍入
向零舍入:向接近0的方向进行舍入。整数向下舍入,负数向上舍入
向下舍入:向下取整
下上舍入:向上取整

在进行数值的舍入时候,对于一个数组,下面三种方法都会产生向上或者向下的均值误差,对样本的分布特点产生影响。而由于向偶数舍入独特的舍入规则,50%的数向上舍入,50%的数向下舍入(如下图所示),对整体数据分布产生的影响较低。

浮点运算
注意:浮点运算并不具备乘法和加法结合律。根本原因在于浮点数运算不是在“真实数集合”上直接进行,而是在有限位数、需要对齐阶码并伴随舍入的机器表示上完成。
以浮点加法为例,两个数相加前往往需要先将较小数的尾数右移,以匹配较大数的阶码;这个过程中可能丢失低位精度。也正因为每一步运算都会发生舍入,(a + b) + c 与 a + (b + c) 就可能得到不同结果。对于乘法、分配律甚至相等比较,也都存在类似问题。
因此,在数值计算中应尽量避免把浮点数当作“精确实数”看待。更稳妥的做法是:理解其误差来源、减少无意义的重复变换,并在比较时使用误差范围而不是直接判断是否完全相等。
强制类型转换规则

附录:数组越界 / Core Dump
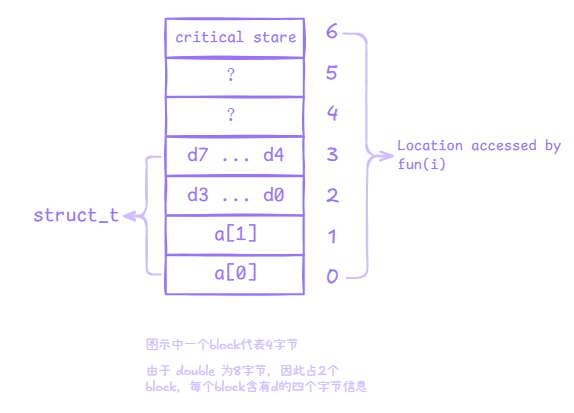
为了更直观地观察数组越界如何影响相邻内存中的对象,可以看下面这段实验代码。它把整数数组和 double 字段放在同一个结构体里,便于观察越界写入后的结果变化。
#include <stdio.h>
#include <stdlib.h>
typedef struct {
int a[2];
double d;
} struct_t;
double func(int i) {
volatile struct_t s;
s.d = 3.14;
s.a[i] = 1073741824;
return s.d;
}
int main() {
int i;
scanf("%d", &i);
printf("%lf\n", func(i));
printf("The size of struct_t is %ld bytes\n", sizeof(struct_t));
return 0;
}对应输入输出
ziyang@LAPTOP-SPPQSEGM:/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1$ ./core_dump
0
3.140000
The size of struct_t is 16 bytes
ziyang@LAPTOP-SPPQSEGM:/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1$ ./core_dump
1
3.140000
The size of struct_t is 16 bytes
ziyang@LAPTOP-SPPQSEGM:/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1$ ./core_dump
2
3.140000
The size of struct_t is 16 bytes
ziyang@LAPTOP-SPPQSEGM:/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1$ ./core_dump
3
2.000001
The size of struct_t is 16 bytes
ziyang@LAPTOP-SPPQSEGM:/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1$ ./core_dump
4
3.140000
The size of struct_t is 16 bytes
ziyang@LAPTOP-SPPQSEGM:/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1$ ./core_dump
5
3.140000
The size of struct_t is 16 bytes
ziyang@LAPTOP-SPPQSEGM:/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1$ ./core_dump
6
*** stack smashing detected ***: terminated
Aborted (core dumped)为什么不同输入值对应返回值不同?
输入 0,1 对应正确修改a[0]、a[1]数值
输入2~3时,程序越界覆盖 double 变量 d的部分字节信息,影响最终 d 的输出结果
很奇怪的是,这里访问a[2]对d的部分字节信息进行复写后,打印的
d值竟然没有改变,Lecture中的值变成了 3.1399998
输入4~5时,程序越界覆盖栈内其它位置的字节信息,但不影响 d 的结果
输入6时,程序越界访问禁止的空间,系统抛出 core dump 异常退出
为什么程序可以直接越界修改d及其它变量的数值?
我们首先要了解,局部变量是储存在栈中的,程序定义的结构体会在栈中分配一段连续的空间。
a[] 指向的是 int 类型数组的首地址,索引每增加1,对应指向的物理地址增加sizeof(int)长度。由于gcc 不对边界进行检查,因此我们能够通过a[2]访问紧接着数组a[1]的变量d。由于d为 double 类型,数组a[]为 int 类型,所以对a[2]、a[3]的修改只改变了d的部分编码表示,因此返回的结果分别为3.140000、2.000001
拓展:加入 -fsanitize=address 编译指令后的输出
ziyang@LAPTOP-SPPQSEGM:/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1$ ./core_dump
4
=================================================================
==778==ERROR: AddressSanitizer: stack-buffer-overflow on address 0x7ff497700070 at pc 0x55fea3b8f3a4 bp 0x7ffc40d74080 sp 0x7ffc40d74070
WRITE of size 4 at 0x7ff497700070 thread T0
#0 0x55fea3b8f3a3 in func (/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1/core_dump+0x13a3) (BuildId: 8528e3c2f6dd941dca3b6a2acda08ba9581d610c)
#1 0x55fea3b8f506 in main (/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1/core_dump+0x1506) (BuildId: 8528e3c2f6dd941dca3b6a2acda08ba9581d610c)
#2 0x7ff4998ac1c9 in __libc_start_call_main ../sysdeps/nptl/libc_start_call_main.h:58
#3 0x7ff4998ac28a in __libc_start_main_impl ../csu/libc-start.c:360
#4 0x55fea3b8f1e4 in _start (/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1/core_dump+0x11e4) (BuildId: 8528e3c2f6dd941dca3b6a2acda08ba9581d610c)
Address 0x7ff497700070 is located in stack of thread T0 at offset 48 in frame
#0 0x55fea3b8f2b8 in func (/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1/core_dump+0x12b8) (BuildId: 8528e3c2f6dd941dca3b6a2acda08ba9581d610c)
This frame has 1 object(s):
[32, 48) 's' (line 8) <== Memory access at offset 48 overflows this variable
HINT: this may be a false positive if your program uses some custom stack unwind mechanism, swapcontext or vfork
(longjmp and C++ exceptions *are* supported)
SUMMARY: AddressSanitizer: stack-buffer-overflow (/mnt/d/a_study/code_vs/CSAPP-test/Chapter_1/core_dump+0x13a3) (BuildId: 8528e3c2f6dd941dca3b6a2acda08ba9581d610c) in func
Shadow bytes around the buggy address:
0x7ff4976ffd80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7ff4976ffe00: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7ff4976ffe80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7ff4976fff00: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7ff4976fff80: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
=>0x7ff497700000: f1 f1 f1 f1 04 f3 f3 f3 f1 f1 f1 f1 00 00[f3]f3
0x7ff497700080: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7ff497700100: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7ff497700180: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7ff497700200: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
0x7ff497700280: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Shadow byte legend (one shadow byte represents 8 application bytes):
Addressable: 00
Partially addressable: 01 02 03 04 05 06 07
Heap left redzone: fa
Freed heap region: fd
Stack left redzone: f1
Stack mid redzone: f2
Stack right redzone: f3
Stack after return: f5
Stack use after scope: f8
Global redzone: f9
Global init order: f6
Poisoned by user: f7
Container overflow: fc
Array cookie: ac
Intra object redzone: bb
ASan internal: fe
Left alloca redzone: ca
Right alloca redzone: cb
==778==ABORTING附
volatile 关键字
告诉编译器,被它修饰的变量的值可能会在程序本身不可见的方式下被改变,阻止编译器优化
在C语言中,volatile 不是变量类型,它是一个关键字(或称为类型修饰符)。
它的主要作用是告诉编译器,被它修饰的变量的值可能会在程序本身不可见的方式下被改变。
具体来说,volatile的作用是:
阻止编译器优化(最主要作用):
为了提高效率,编译器通常会对代码进行优化,比如将变量的值缓存在 CPU 寄存器中,而不是每次都从内存中读取。
如果一个变量被声明为
volatile,编译器就会知道这个变量的值可能会在任何时候被外部因素(例如:硬件、中断服务程序、多线程中的其他线程)改变。因此,编译器会禁止对该变量的读写操作进行这种优化,确保每次访问该变量时,都会直接从内存中读取最新的值,并且每次写入都会立即写入内存。
应用场景:
内存映射硬件(Memory-Mapped Hardware):例如,读写硬件寄存器时,寄存器的值可能会随时改变。
中断服务程序(Interrupt Service Routines, ISR):一个全局变量可能在一个主程序循环中被访问,同时又在一个中断服务程序中被修改。
多线程应用(虽然在C语言标准中不保证多线程同步,但在特定编译器和环境下仍有其作用):用于标记一个共享变量,防止编译器优化导致读到旧的缓存值。
总结:
volatile是一个类型修饰符,而不是一个独立的变量类型。它的目的是确保对变量的访问是直接且即时地与内存进行交互,从而避免因编译器优化而导致的程序错误,特别是在涉及外部改变变量值的情况下。
volatile int status_flag; // status_flag 是一个整型 (int) 变量,并用 volatile 关键字修饰GCC 不会自动检查数据越界,除非加编译选项
GCC 默认不检查数据越界:在默认编译选项下,GCC 不会主动对数组访问、指针操作等进行数据越界检查(包括编译期和运行期)。这是因为 C/C++ 标准未要求编译器提供此类检查,且出于性能考量,默认不启用。
编译选项可增强检查:通过特定编译选项,GCC 可以引入一定的越界检测能力,例如:
-fsanitize=address:启用 AddressSanitizer 工具,能在运行时检测多种内存错误(包括越界访问),并给出详细报告(但会增加程序体积和运行开销)。-Wall等警告选项:可对一些明显的越界风险(如数组初始化长度不匹配)给出编译警告,但无法覆盖所有情况。
界可能导致 core dump:数据越界属于未定义行为(UB),可能引发包括 core dump(段错误)在内的各种后果,但并非必然。例如,越界访问未超出进程地址空间的区域时,可能不会立即崩溃,而是导致数据损坏等隐蔽问题。
字长
定义:字长(Word Size),又称字宽(Word Width)或字长长度(Word Length),是计算机系统架构中一个最基础且最重要的概念之一。它定义了计算机在单个操作中能自然处理的数据量。
逻辑运算符和位运算符的区分
|、&、~、<<、>> 出现的运算式为位运算式;||、&&、! 出现的运算式为逻辑运算式。在阅读 C 语言表达式时,先判断运算符属于“按位操作”还是“逻辑判断”,往往比直接记忆优先级更重要。
&、*、[](数组操作符)与指针
指针的本质就是存储一串物理地址的变量。在 C 语言中,与指针操作紧密相关的包括 &、*、[] 三种操作符:
&:获取变量对应的内存地址*:根据地址取出目标位置上的值[]:基于首地址和步长访问偏移后的元素
总结
理解信息的表示与处理,本质上是在理解“同一串位模式如何在不同规则下被赋予不同含义”。第二章从字节序、整数编码、补码运算,一路推进到 IEEE 754 浮点数表示,展示了计算机并不是直接处理数学对象,而是在有限位宽、固定规则和工程权衡之下处理编码后的近似结果。
对于整数而言,最关键的是掌握位模式与数值解释分离这一点:无符号数和补码往往共享同一底层比特串,但由于权重体系不同,会得到完全不同的数值意义。这也是强制类型转换、符号扩展、溢出与移位问题容易出错的根源。只要位宽是有限的,整数运算就必然受到模运算语义的约束。
对于浮点数而言,需要额外接受一个事实:它追求的不是“绝对精确”,而是“在有限位数内尽可能覆盖更大动态范围”。规格化数、非规格化数、无穷大与 NaN 共同构成了一套工程上可用的近似表示体系。也正因为如此,浮点运算会出现舍入误差、精度损失、不满足结合律等现象,而这些现象并不是实现缺陷,而是表示方法本身决定的结果。
回到编程实践,这一章最重要的启发并不是背下多少公式,而是建立一种位级视角:当程序出现越界、溢出、比较异常或类型转换反直觉时,不要只停留在高级语义层面,而要追问“这串比特此刻是如何被解释的”。一旦形成这种思维方式,很多看似诡异的程序行为都会变得可以分析、可以验证、也可以规避。